AI and machine learning with British Library collections
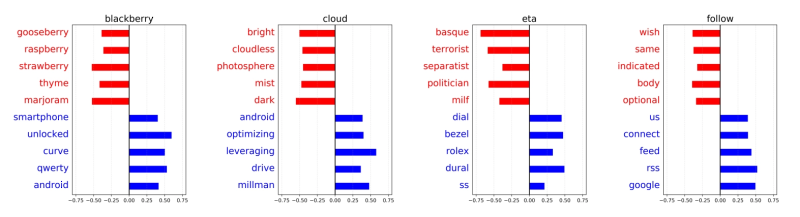
Machine learning (ML) is a hot topic, especially when it’s hyped as ‘AI’. How might libraries use machine learning / AI to enrich collections, making them more findable and usable in computational research?
23 December 2024